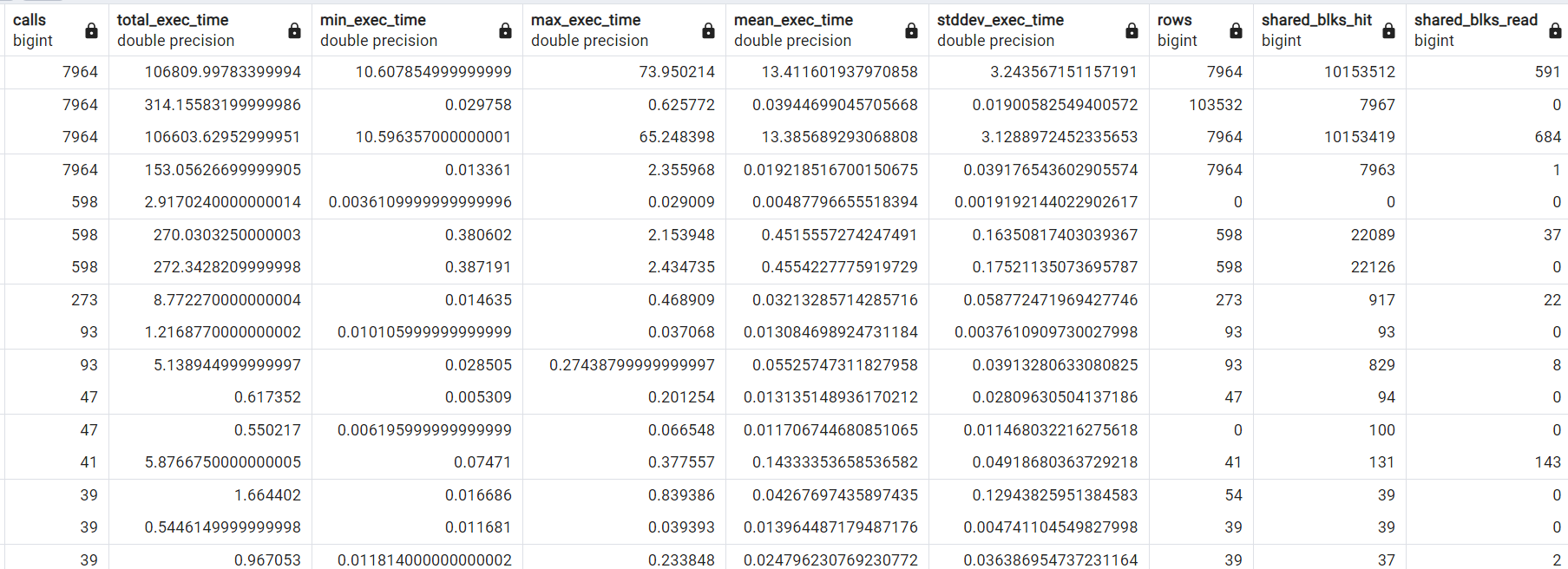
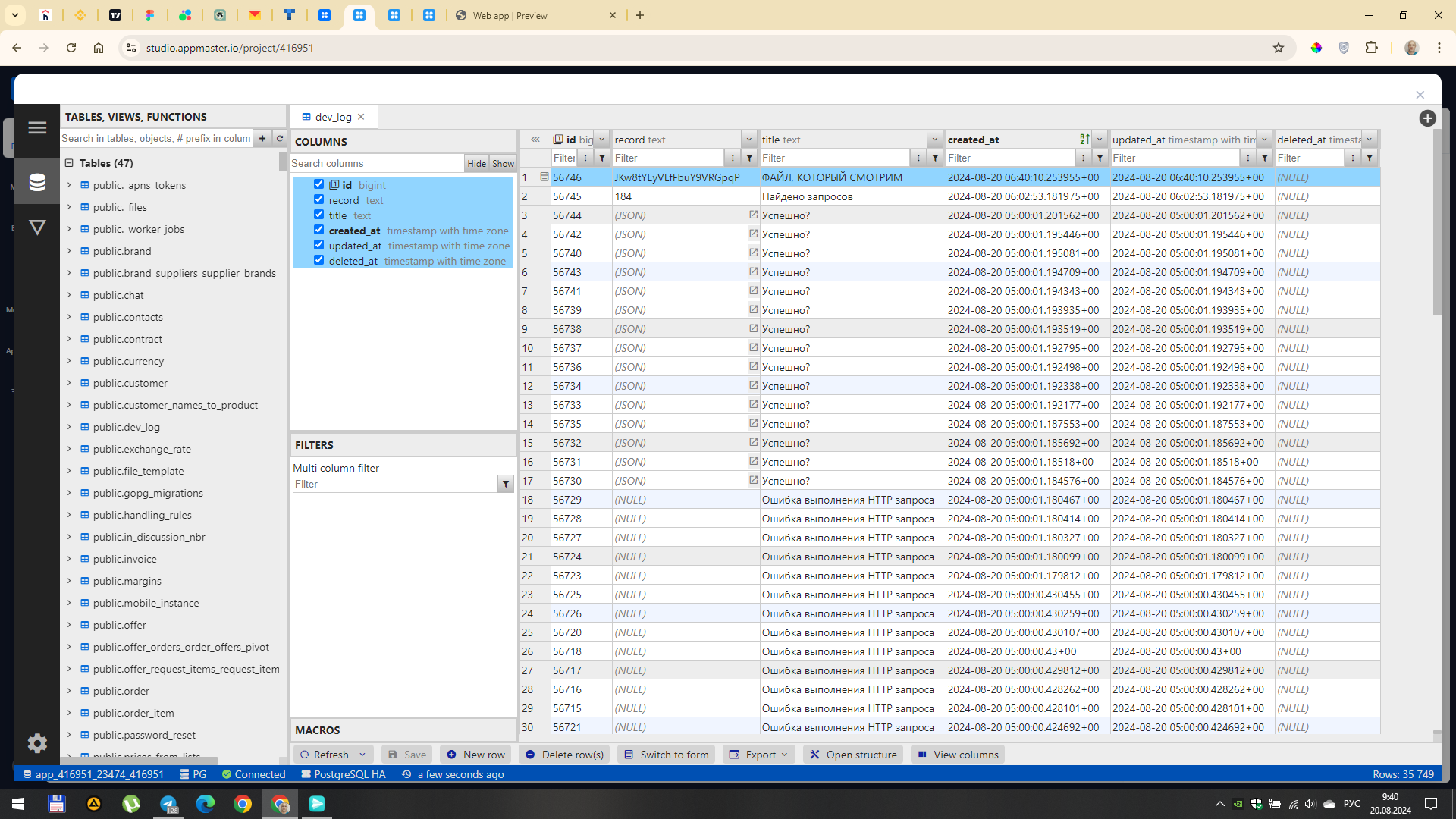
При попытке прочитать xlsx файл ничего не получается. БП упростил до минимума, чтобы хотя бы понять на какой строчке процесс отваливается, но по результатам получается, что файл вообще не был прочитан. На скринах видно:

Вылили правки, проверьте у себя
Расставьте логи, посмотрите где что не передаётся
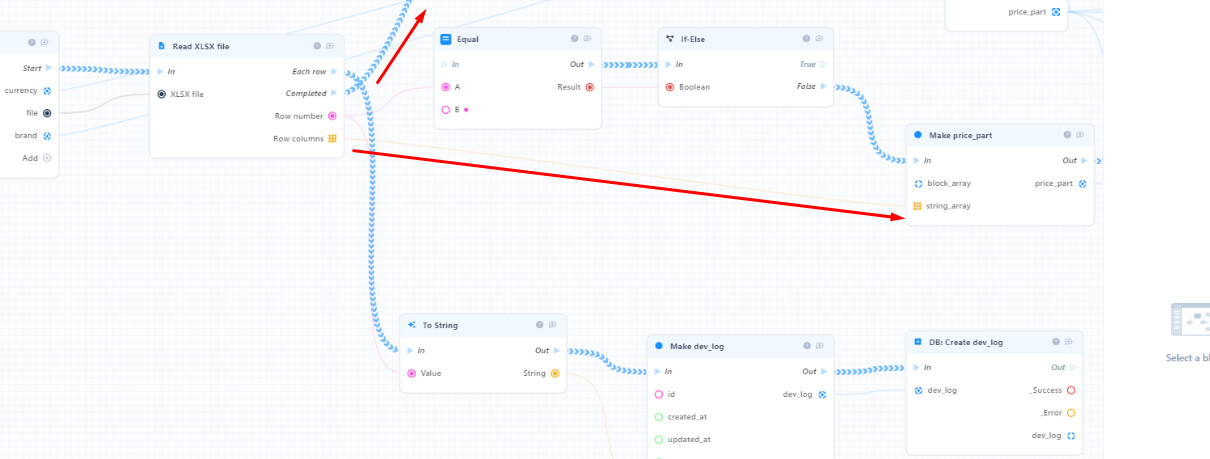

@Alexandr_Yaskunov
Судя по контексту у вас может быть 1 из двух проблем:
- отваливается запрос по таймауту через определенное время
- происходит событие OOM (Out-of-memory) и контейнер перезапускается
Вы импортируете более полумиллиона записей в БД по одной? Если да, то я настоятельно рекомендую использовать SQL Exec и импортировать батчами - подробнее можно спросить у GPT. Вне зависимости будете ли вы использовать наше облако или переедите на выделенный хостинг у вас проблема останется - очень долгий импорт без батчинга.
Чтобы проверить попробуйте протестировать несколько кейсов:
- Уменьшите размер файла импорта до 10% от оригинала, проверьте время
- Увеличивайте размер пока не будет падать
- Добавьте батчинг (например по 1000 записей), продолжайте увеличивать размер
Пользователю и не нужно ничего дробить. Ваша задача как разработчика использовать оптимальный метод импорта - тогда и у пользователей проблем не будет.
Пожалуйста изучите техническую часть как работает PostgreSQL, что такое индексы, для чего они нужны, как быстрее вставлять большое количество данных. Пока вы работаете в десятками тысяч записей - с дефолтными настройками все хорошо будет работать, но по мере роста вам требуется выполнить больше настроект чтобы на больших объемах все работало.
Небольшой пример:
Если нет индекса в фильтре, то СУБД придется при выборе данных просканировать всю таблицу последовательно и если у вас там много данных (а 100к+ записей это уже достаточно) только один такой запрос может занять до 10 секунд. Однако верно и обратное: если вы накидаете кучу индексов необдуманно, то это приведет с сильному разрастанию размера БД и очень очень медленной вставке из-за пересчета всех индексов в таблице.
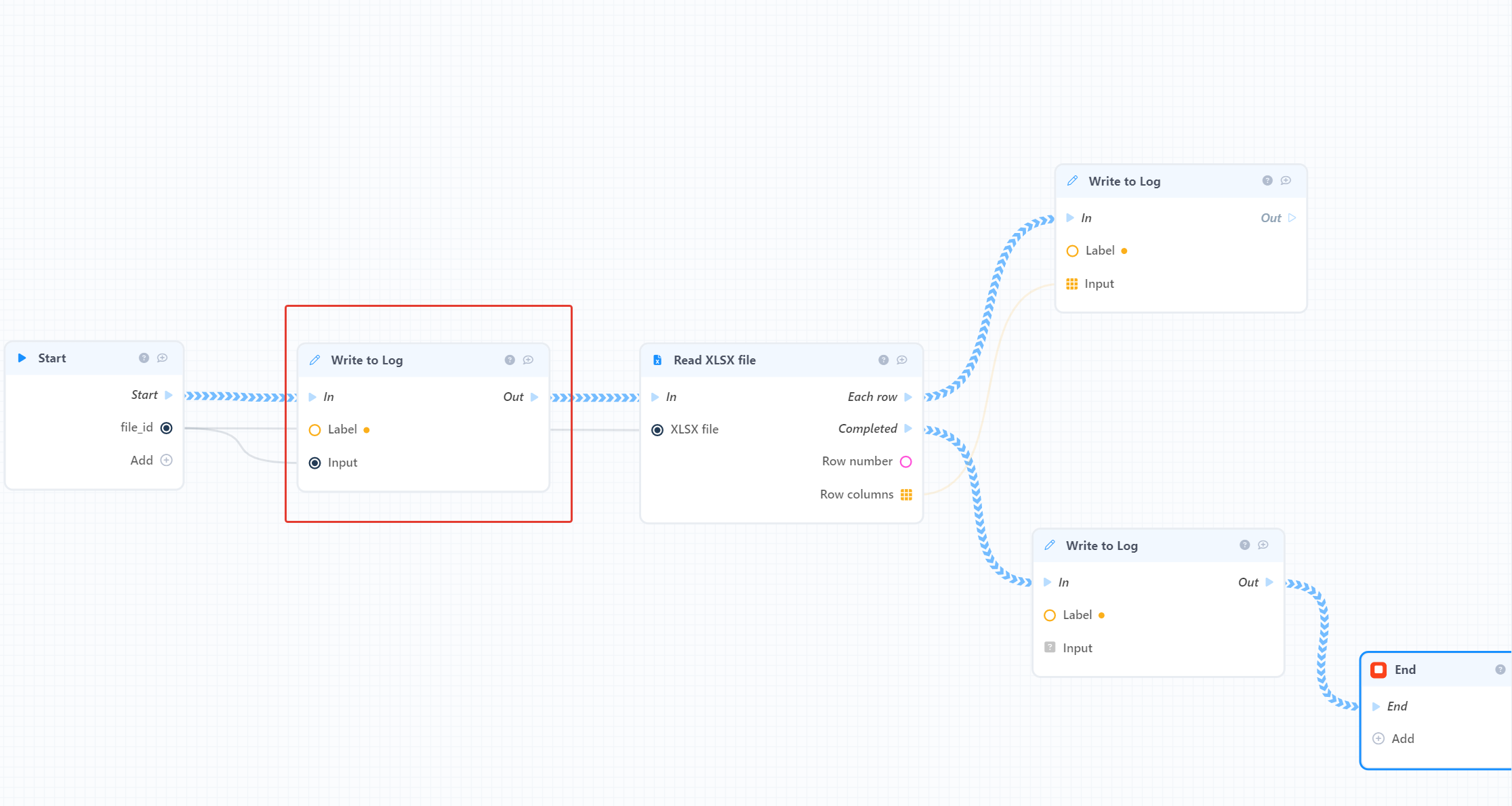
У вас ошибка возникает на бэке, чтобы ее найти нужно поставить логи как минимум в указанных на моем скриншоте местах.
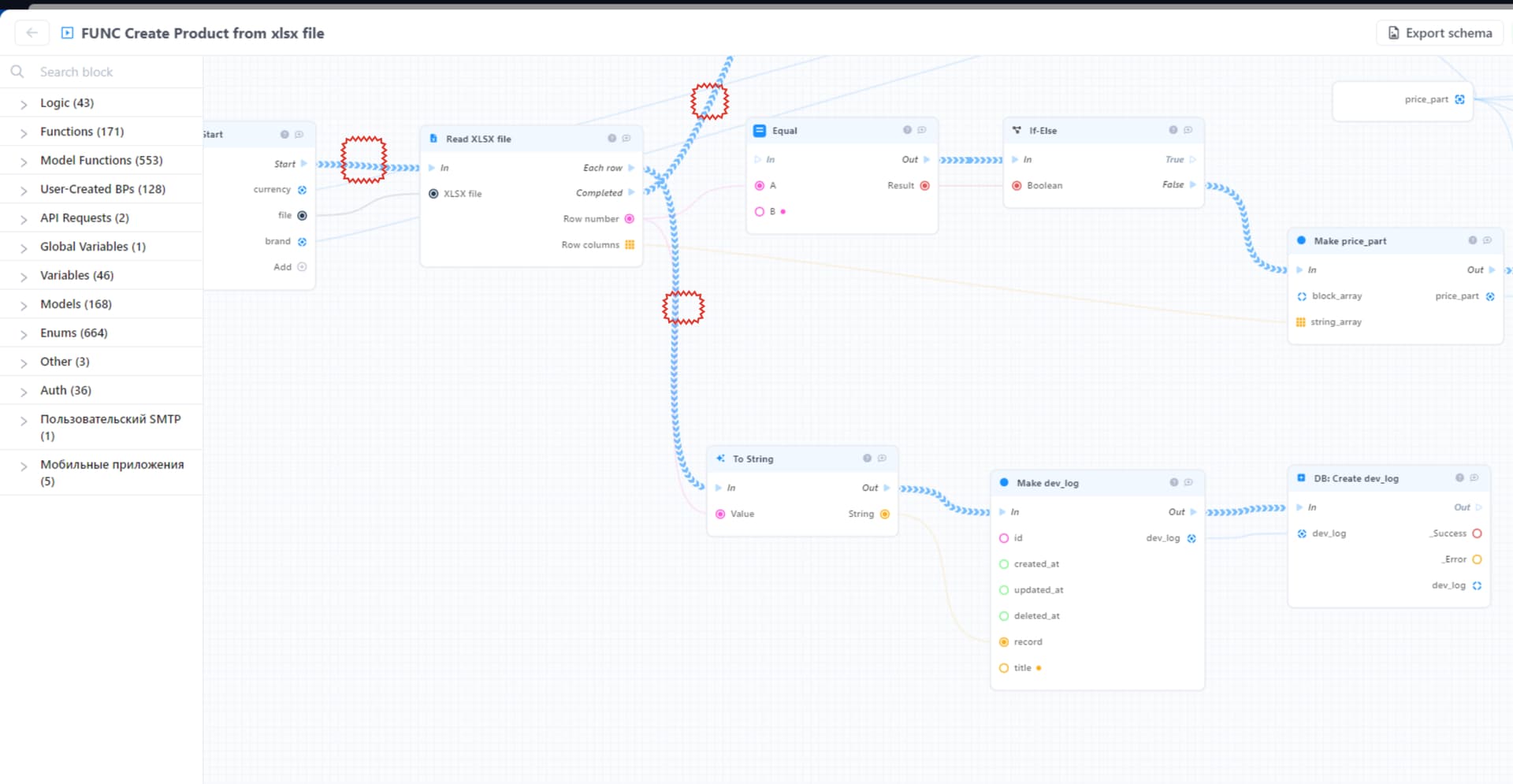
Для отображения логов используйте системный блок “Write to log”, он поможет понять что происходит с БП в контексте конкретного запроса.
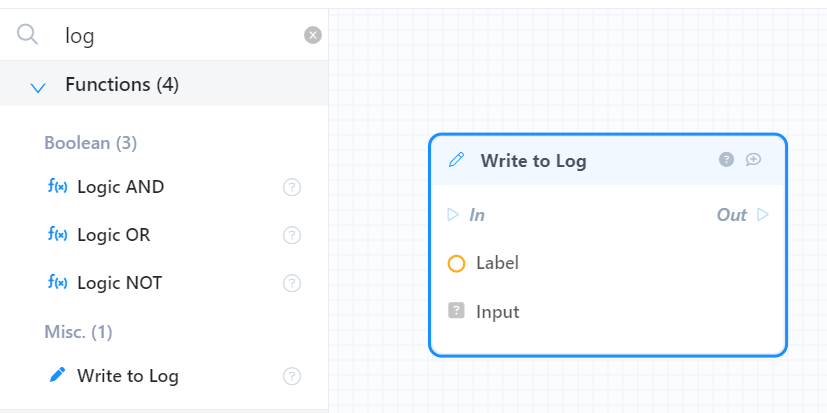
В этом блоке в Label можно написать любой текст, который будет отображаться в логах например в зависимости от места расположения - старт БП, вход в цикл, выход из цикла и т.п.
Дальше в логах нужного деплой плана включите все типы логов и смотрите что происходит с выполнением БП.
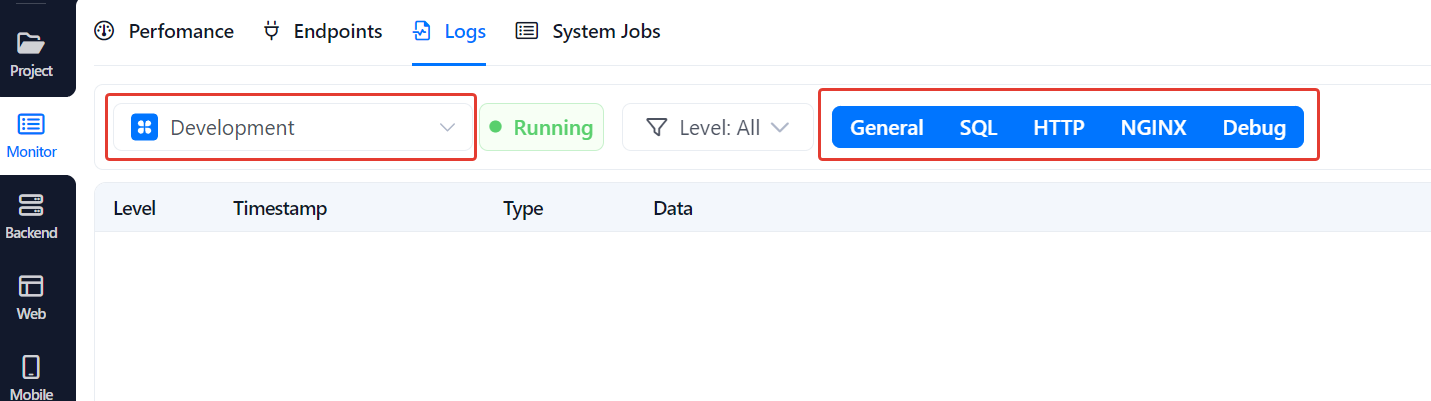
Т.е. у вас в логах должны будут последовательно отобразится отдельными строками каждый вызов блока “Write to Log” и таким образом можно будет понять на каком месте вообще происходит прерывание выполнения БП.
После этого можно будет уже начать разбираться, что же вызывает ошибку.
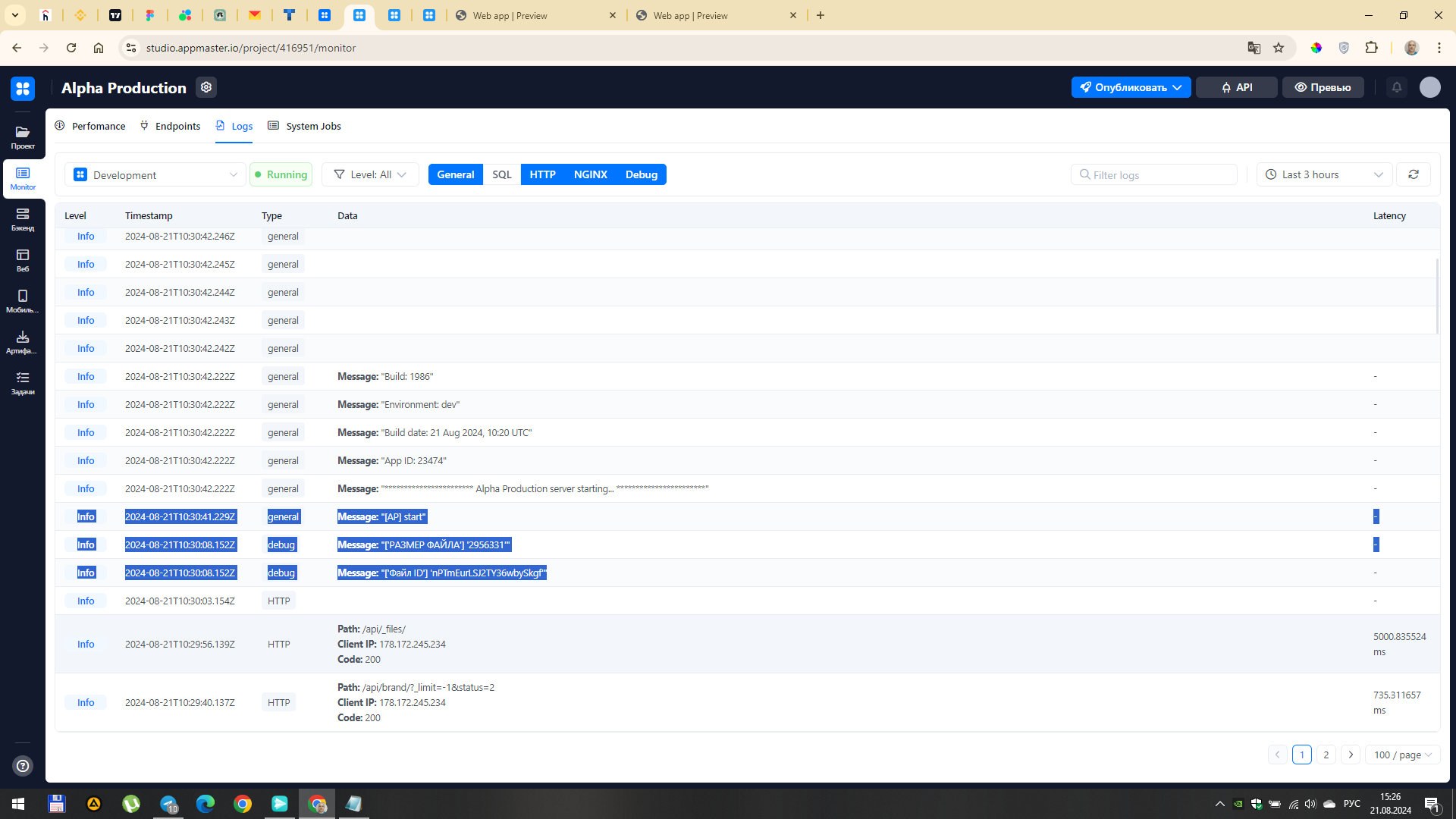
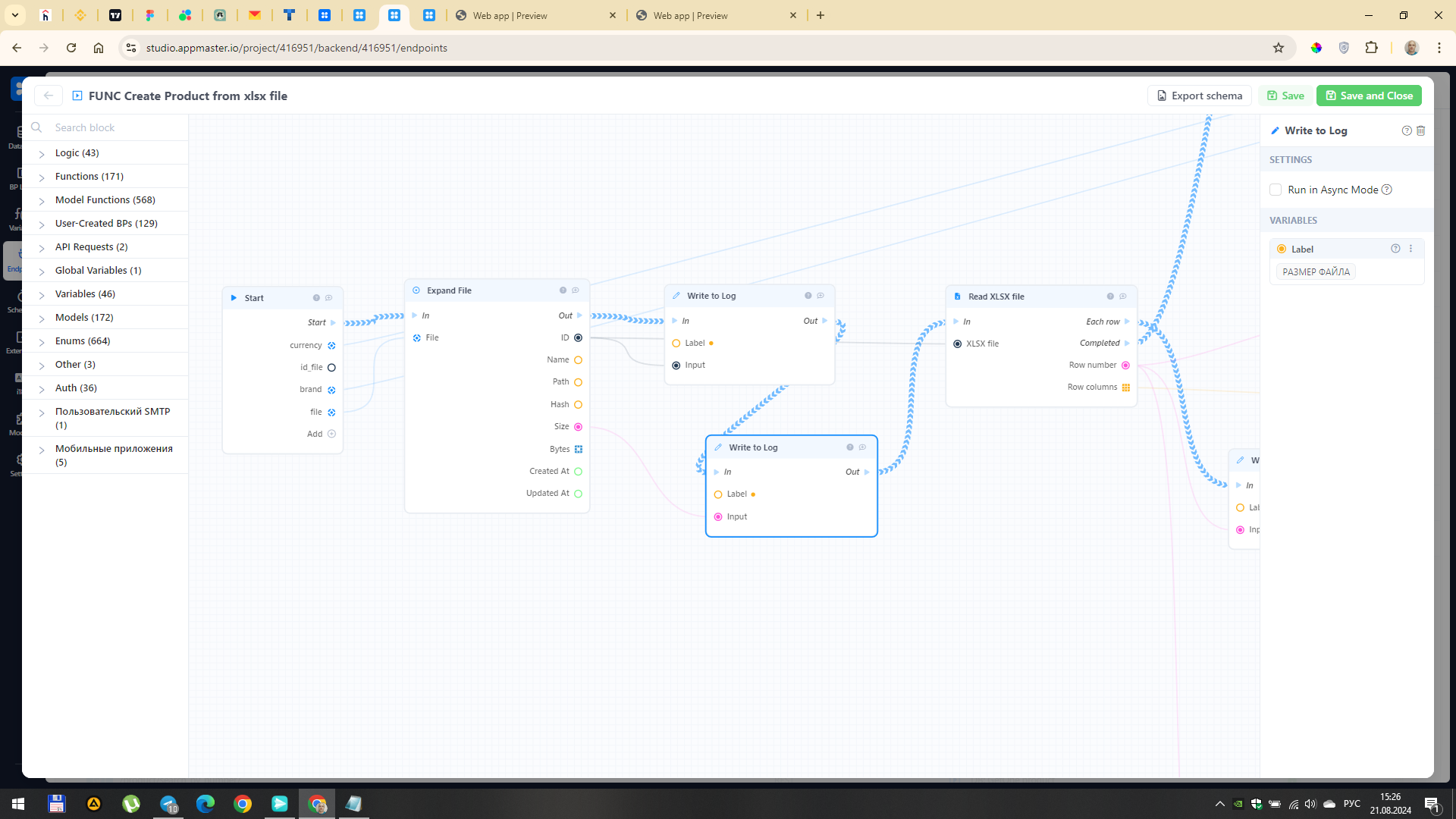
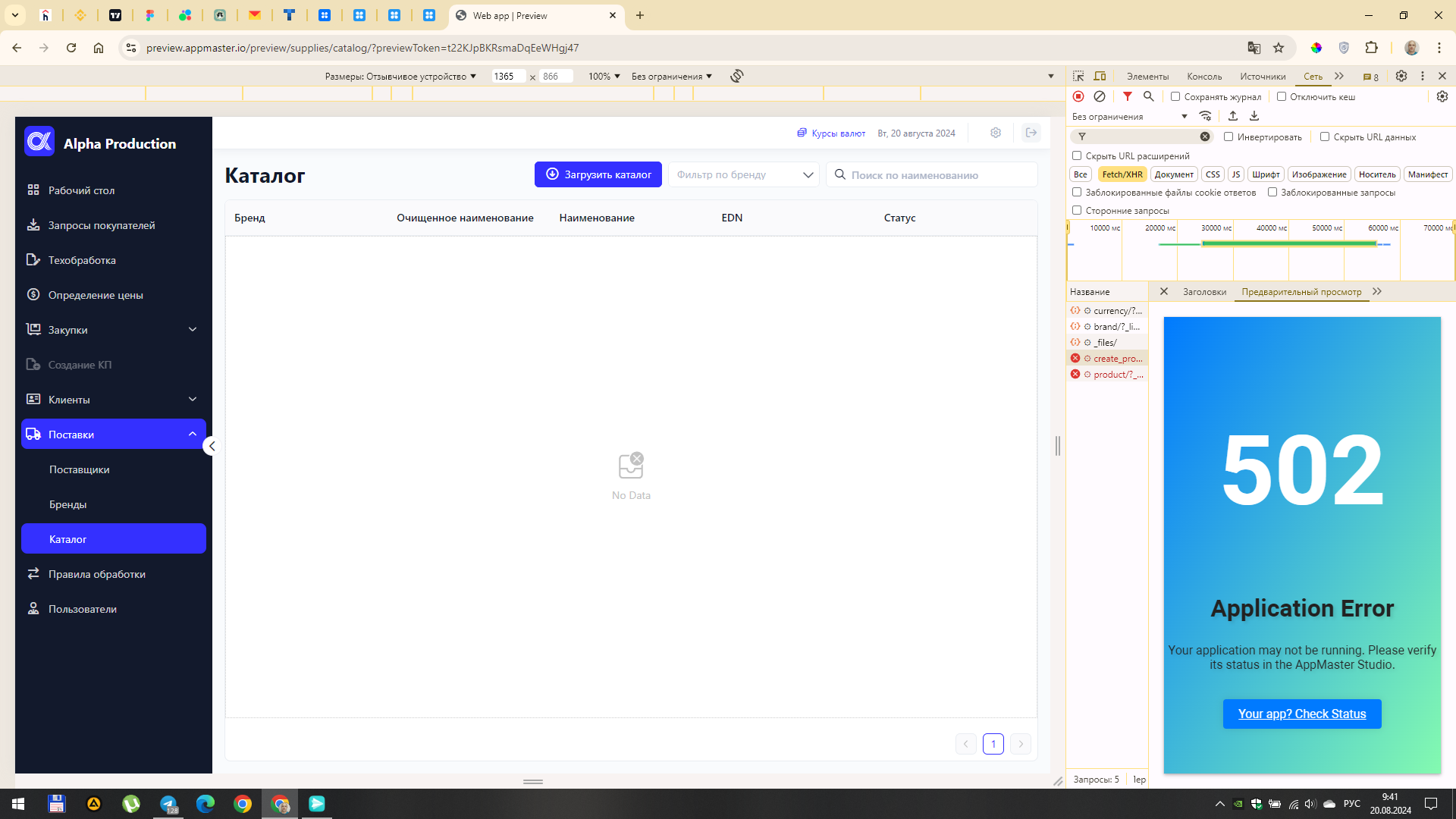
После запуска БП видно, что файл приходит (есть его id и размер) а дальше приложение почему-то перезапускается. Естественно, ничего больше не происходит
@anthony.appmaster я проверил на тестовом приложении, у меня такая же ошибка как у Александра. Процесс падает на этапе открытия файла.
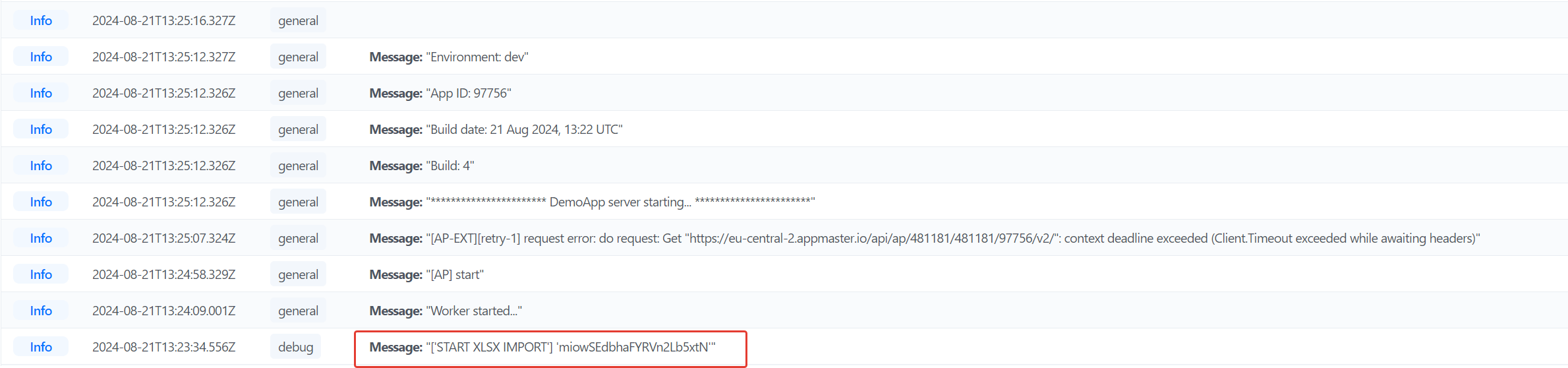
В лог попадает только один блок, при запуске БП дальше даже до первой строки не доходит.
Коллеги, добрый день. Скажите пожалуйста, в работе ли у вас вопрос, есть ли прогресс/ожидания по решению?
Доброе утро. Скажите пожалуйста хотя бы, что задача у вас в работе и не на последнем месте. Надо подождать неделю - подождём.
@S.V @Alexandr_Yaskunov
По состоянию на сегодня проблема не решена? Все еще падает и падает в том же месте что и раньше?
Резюме по этой проблеме.
Изначально мы неверно классифицировали проблему, мы думали что таймаут вызывается долгими операциями с СУБД. Однако после дебаггинга выяснилось что это событие OOM (Out-of-memory, превышение доступной памяти в контейнере приложения).
Реальная проблема оказалась в библиотеке, которую мы использовали для чтения и парсинга XLS файлов (мы ее не писали). Эта библиотека реализует полноценный функционал работы с XLS, включая расчет формул, ссылки и т.п. Функционал сложный, большой и в отдельных случаях требующий большого количества памяти для обработки файлов. Скорее всего поэтому мы видели кейсы когда большие файлы с множеством строк работали корректно, а некоторые маленькие падали.
Мы заменили библиотеку на другую, без полноценной поддержки всего функционала XLS - теперь только чтение самого файла, без расчетов и ссылок. Должно работать даже на самых больших файлах в миллионы строк без отклонений.
Что касается батчинга и индексов - рекомендации в силе. Проверьте как долго выполняются операции с БД и если они выполняются долго, добавляйте батчи.